In a microservices architecture, data is typically distributed among different services, each with its own database. Implementing a multi-level search across these microservices can be challenging. The goal is to efficiently search and aggregate data from different microservices while ensuring optimal performance, scalability, and cost-effectiveness.
- Solutions
Selective Replication pattern:
In this approach, we replicate the data needed from other microservices into the database of our microservice.
- Selective Replication: Only replicate the data that is frequently accessed together. For example, if we often need to know the status of tasks associated with an instrument but not other details, only replicate the task status.
- Event-Driven Updates: data will be kept in sync using an event-driven approach. For example, when a task is created or updated, it could publish an event that the Instrument service listens to and then updates its own records accordingly.

Tasks Table: In the Instrument module, We could have a table that stores task details associated with an instrument. This could include the task ID, status, type, etc.
Pros
- Optimized Performance: By replicating frequently used data, we reduce latency and improve user experience.
- Reduced Network Calls: This approach minimizes the number of cross-service calls for common operations.
- Flexibility: We have the flexibility to fetch detailed data when necessary.
Cons
- Cross Service Calls The idea is to replicate only the most frequently accessed and critical attributes to optimize performance and reduce cross-service calls. However, for attributes that are less frequently used or for details that require a more comprehensive view, we might still need to make calls across microservices.
API Composition Pattern
In this approach, ApiGateway(or a composite microservice) aggregates data from multiple services and returns a unified response. This pattern is useful when we want to fetch data from different microservices in a single API call without the need for data replication. For Example - Details of an instrument along with the tasks associated with that instrument

Flow
- The client requests details about an instrument, including its associated tasks.
- The request is received by the API Gateway or a Composite Microservice, which acts as an orchestrator.
- The API Gateway first calls the Instrument Management microservice to fetch details about the requested instrument.
- After obtaining the instrument details, the API Gateway calls the Task microservice to fetch tasks associated with the instrument.
- The API Gateway aggregates the instrument details and the associated tasks into a unified response.
- The aggregated response is sent back to the client.
Pros
- Single API Call: The client can fetch data from multiple microservices with a single API call, simplifying client-side logic
- Flexibility: The API Gateway can tailor responses to the specific needs of different clients.
- Decoupling: Microservices remain independent and can evolve without affecting the client-side code.
Cons
- Memory: It might not be suitable for complex queries and large datasets that require in-memory joins.
- Complexity: The API Gateway may need to implement complex orchestration and error-handling logic.
- Dependency: If one microservice is down, it could potentially affect the entire operation.
- Error Propagation: Errors from one microservice need to be gracefully handled and communicated to the client.
Search Microservice
The Search Database typically contains a subset of the data from the other microservices, optimized for search operations. It may not have all the data but instead holds indexed, denormalized, or transformed data that is required to fulfill search requests quickly and efficiently.
- The microservices publishes events (SNS/SQS) when data changes.
- The Search Microservice subscribes to these events and updates its data in real-time or near-real-time.
- The Search Microservice processes and indexes the fetched data in a database
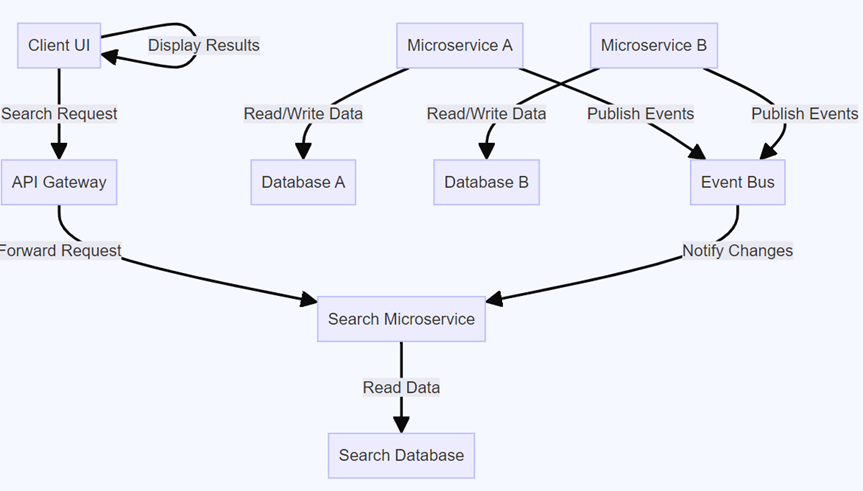
Flow
- A client (e.g., a web application) initiates a search request with specific criteria.
- The request may first go through an API Gateway, which routes the request to the appropriate microservice.
- The Search Microservice processes the search criteria and queries the indexed data.
- If necessary, the Search Microservice aggregates or transforms the data to match the desired response format.
- The Search Microservice sends the search results back to the client.
- The client displays the search results to the user.
Database Aggregator
A central database is used to aggregate and store data from different microservices, providing a unified point for querying and retrieving data.
Each microservice owns its data and performs its business operations as usual. Data from these microservices is then aggregated into a central database.
Event-Driven Updates:
- Microservices can publish events when data changes (Create, Update, Delete operations).
- The central database subscribes to these events and updates its records accordingly.
Search and Query:
- When a multi-level search request is made, the system queries the central database, which contains aggregated data from all microservices.
- The central database can be optimized for search operations, facilitating complex and cross-cutting queries.
- Query: The central database can also be queried directly to fetch and search data.
- Pros
- Simplified Queries
- Performance
- Loose Coupling
- Cons
- Complexity
- Data Consistency:
- Storage Overhead


